Recent Retail IT Outages or The Importance of Being Resilient
News and information from the Advent IM team.
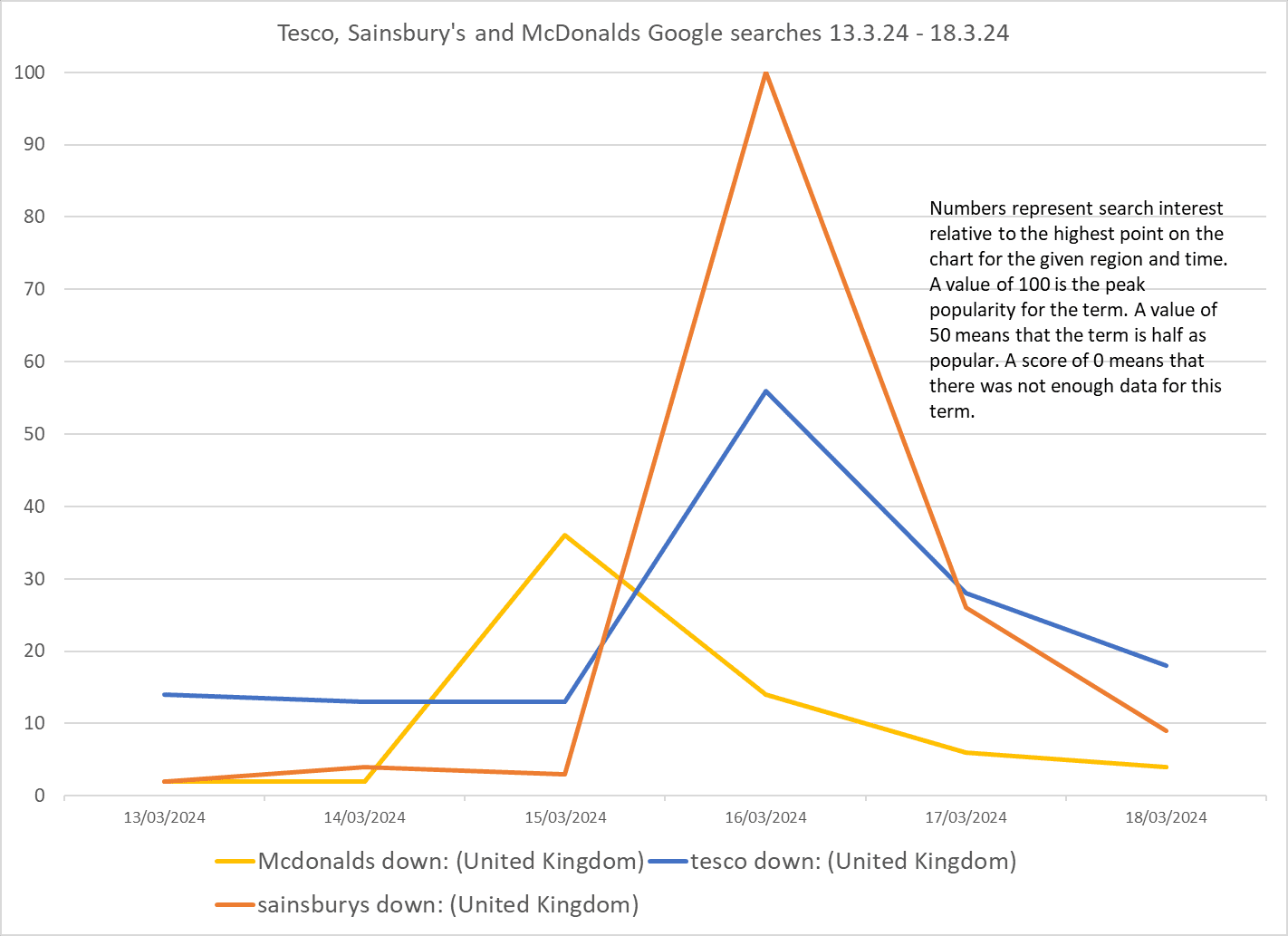
IT-based outages affecting McDonald’s, Sainsbury’s and Tesco were widely reported last weekend (15th and 16th March 2024), with many confused and angry customers taking to social media to warn others or make contact with the brands, seeking more information.
What did it look like, by brand?
McDonald’s customers were unable to order food following an IT system outage in its stores, and stores in the UK, Australia, New Zealand, and Japan (NB chart covers UK searches only) had to be closed. The issue has been blamed on a third-party configuration change. The problems with McDonalds appear to have started before the supermarkets, however and generated the highest level of search queries on Google.
Sainsbury’s was forced to cancel home deliveries and some stores were unable to take contactless payments due to its IT outage, which, according to the company, may have affected £9m worth of orders. In a statement Sainsbury’s said that the “error” was caused by an overnight software update.
Tesco said it was forced to cancel online orders due to a “technical issue” although it is not yet clear just what that technical issue involved.
Hardly statements awash with information and reassurance.
All three companies have apologised to customers affected, and it was widely reported that there was no connection between them. I disagree.
With the growing levels of complexity in many organisation’s business systems, system resilience is more important than ever. Unfortunately, there is often a disconnect between IT Change and Configuration Management, Business Continuity Planning and System Resilience thinking. Applying software changes, whether that is altering a configuration, applying a software update or even adding security patches to a major live system ought to involve significant and coordinated planning, with deployment into a test environment first. For this to be effective the test environment, including its data, needs to closely replicate that of the live environment. Alongside the testing there needs to be adequate rollback procedures, again these are developed and proven in the test environment.
Finally, there needs to be an effective business continuity plan in place that kicks in when the unexpected happens.
These recent outages are not the only examples.
In recent times we have seen the UK Air Traffic Control system taken offline for 9 days resulting in 2000 flights being cancelled, banking systems being unavailable including most recently HSBC online and mobile banking services as well as its anti-fraud system being offline on one of the busiest online shopping days of the year – Black Friday, and several widespread outages in social media platforms.
As we as individuals, and society as a whole, become ever more dependent on the technology that enables our lives and businesses to thrive, the organisations owning and managing these technologies must do more to invest in system resilience.
Of course, all of this, costs. It costs investment in infrastructure and software, it requires properly skilled people and it costs in terms of time and resource. It requires well informed, capable leadership that support this best practice. However, at what cost the alternative?